

 RSS Feed
RSS FeedBlog > Post
Data Modeling in Document Databases for the RDBMS-Minded
by Cihan Biyikoglu (guest author), 7 December 2015
Tags:
What is Data Modeling?
Data modeling is the exploration of the structuring of your data. The exercise is astonishingly similar to designing and constructing buildings;
Depending on what type of utility you want to serve (libraries vs opera houses vs gyms) and what interactions you want to optimize (company HQ for employees, residential buildings such as high rises or single family homes), you plan your walls, optimize flows within the structure and finally, you choose the material that can turn the design into reality!
All this applies directly to data modeling as well! The exercise involves understanding both the application requirements and the underlying database platform. Application logic and its data flow leads to the entities and relationships in the data model. The database platform provides the “material” to represent the logical entities with methods to store and retrieve instances of the entities. Materials can make a huge amount of difference in how fast you can construct your design and how easy it can be to reconfigure parts of the builds to fit the tenants! For the rest of the paper, we’ll focus on a new material: document databases and the flexibilities it brings to constructing and evolving your data model.
I will assume most of you are familiar with relational databases and the general properties of the “material” there. RDBMSs provide tables with columns to represent entities and require advance declaration of schema before storing data. The “tenants” that want their own customizations find it hard to evolve this pre-declared schema. A “product catalogue” table can be a nightmare for relational databases. Products share properties like “price” but representing properties of a sports car in one row and vacation package in another row require difficult acrobatics in RDBMS world. On the other hand, document databases use JSON formatted documents and allow great flexibility. Each document carries its own schema and can nest complex structures like “embedded documents” and “array of documents”. You can easily represent the attributes like colour for the car in one document and represent valid travel dates for the vacation package in another document and let the application drive the schema evolution without requiring in-advance declarations.
One last important point before I get started: Some relational and NoSQL databases retrofit JSON type as a data type into their type system (see SQL Server JSON support, Oracle JSON support or late addition of JSON Cassandra JSON support) and shred it to fit into the native data model of the underlying system. Instead, I will be focusing on native document databases like MongoDB, Couchbase and alike.
Data Modeling with Document Databases
Data modeling exercise in document databases isn’t all that different from what you do with relational schema based databases. One goes through the same 2 phases in either case:
- Logical data modeling: This phase focuses on describing your entities, their attributes and relationships. Logical data modeling phase is independent of the underlying containers your database platform provides.
- Physical data modeling: In this phase you take the logical design and apply the entities and relationships to the containers provided to you by the document database. Based on the access patterns, performance requirements and atomicity and consistency requirements, you choose which type of containers to use to represent your logical data model.
Logical Data Modeling
The logical data modeling phase focuses on describing your entities and relationships. Logical data modeling is done independently of the requirements and facilities of the underlying database platform. You can find various methods of data modeling here: https://en.wikipedia.org/wiki/Data_modeling.
At a high level, the outcome of this phase is a set of entities (objects) and their attributes that are central to your application’s objectives, as well as a description of the relationships between these entities. Imagine an aerospace application: entities may be “satellite”, “module” and “instrument,” where their relationships might be “satellites carry many modules, which in turn are made up of many instruments”. Relationships can vary in type: one-to-many or many-to-many or one-to-one.
Here are the main building blocks of the logical data modeling exercise:
- Entity Keys: Each entity instance is identified by a unique key. The unique key can be a composite of multiple attributes or a surrogate key generated using a counter or a UUID generator. Composite or compound keys can be utilized to represent immutable properties and efficient processing without retrieving values. The key can be used to reference the entity instance from other entities for representing relationships.
- Entity Attributes: Attributes can be any of the basic types such as string, numeric, or boolean, or they can be an array of these types. For example, a satellite might define a number of simple attributes such as name and weight, as well as a complex attribute called launch which in turn contains the attributes, “launch-date” and “launch-site”.
- Entity Relationships: Entities can have 1-to-1, 1-to-many or many-to-many relationships. For example “a satellite has many modules” is a 1-to-many relationship.
Physical Data Modeling
The physical data model takes the logical data model and maps the entities and relationships to physical containers. In document databases, JSON formatted documents are used to store instances of entities with an associated unique key. Document databases also provide “databases” or “buckets” to group documents.
Based on the access patterns, performance requirements and atomicity and consistency requirements, you choose which type of containers to use to represent your logical data model. At a high level comparison of concepts in document vs relational databases may help here:
| Relational Databases | Document Databases |
| Databases | Databases or Buckets |
| Tables | Collections or Type Signifiers |
| Rows | Documents |
| Columns | Attributes |
| Index | Index |
Databases or Buckets: Databases or Buckets group documents just like relational databases group tables. Databases/Buckets are primarily used to control resource allocation and to define security and storage properties. For data with differing availability requirements, IO priorities or caching requirements, databases/buckets act as the control boundary.
Some document databases allow more than just JSON documents as the value associated with the unique key. These multi-model databases allow mixing of non-JSON and JSON values in a single database/bucket for further flexibility. For example, Couchbase Server provides full support for binary values for fast access and JSON documents for representing complex entities.
Documents: Documents consist of a key and a JSON document.
- Keys: Each document is identified by a unique key. The key is typically a surrogate key generated using a counter or a UUID generator. You may also choose composite or compound keys. However typically keys are immutable. So make sure your composite list of attributes is picked from properties that don’t change over time.
- JSON documents: JSON provides rich representation for entities. Document databases can parse, index and query JSON values. JSON document attributes can represent both basic types such as number, string, boolean, and complex types including embedded documents and arrays.
Entity Relationships and Document Design
Logical data modeling starts with a decision on how to map your entities to documents. JSON documents provide great flexibility in mapping 1-to-1, 1-to-many or many-to-many relationships.
- At one end, you can model data so that each entity is normalized to separate documents with references to other document’s key to represent relationships. Similar to relational schema design, in this model you map each “customer” to a document, “order” to another document and order line items to another set of documents that are referenced from the “order” document.
- At the other end, you can embed all related entities into a single large document. That is where a “customer” is a document that embeds all orders with order line items as an array of documents in the “customer” document.
The right design for your application usually lies somewhere in between these two extremes. How these alternatives shall be balanced, depends on the access patterns and requirements of your application. Let's discuss when you’d reference (normalize) vs embed (denormalize) in the document model.
Referencing vs Embedding Documents
Referencing Documents
You can reference another document using the document key. This is similar to normalization in relational terms. Referencing enables document databases to cache, store and retrieve the documents independently. For example with entities like “beers” and “breweries”, you can store beers in a document of their own and reference breweries from the beer document with a brewery_id attribute.
In relational databases referencing is expected and is the norm. Embedding is not typically supported. In some document databases (like MongoDB), referencing is discouraged due to limited support for JOINs, UNNEST/NEST operators, array expressions and subqueries. However, there are SQL implementations available that can exploit the full flexibility of JSON structures like SQL++ and Couchbase Server’s N1QL. The new extensions to SQL allow for full JOINs, UNNEST/NEST operators, array expressions and subqueries. so that data modellers are free to choose referencing or embedding, whichever is the best option for their case, without complicating code development.
Referencing can be beneficial in a numbers of cases:
- Referencing is advantageous if related items are NOT frequently accessed together.
- Referencing can optimize memory, storage and replication as it prevents repetition of brewery attributes across many beers.
- Referencing can help with information consistency and update efficiency for referenced document.
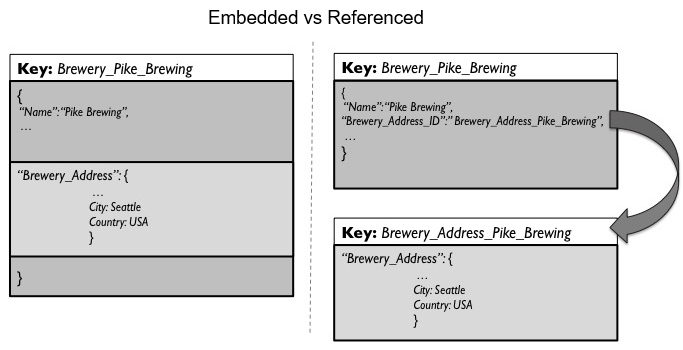
Embedding a Document:
You can embed a document in another document by simply defining an attribute to be an embedded document. This enables document databases to cache, store and retrieve the complex document with embedded documents as a single piece. For example “orders” document can embed “order line items” document by embedding an array called order_line_items in the order document .
In relational databases embedding is not typically supported. In some NoSQL solution embedding is typically overemphasized as JOINs and subqueries are not supported in the platforms and code development gets complicated with referencing. However new SQL extensions in languages like SQL++ or Couchbase Server N1QL, allow full flexibility for embed vs reference approach in document databases.
Embedding can be beneficial in a numbers of cases:
- Embedding can be advantageous when related items are frequently used together. The order_line_item example above eliminate the need to retrieve 2 separate documents and join them.
Modeling Relationships
1-to-many and many-to-many relationships are commonly discussed in data modeling literature and can be a great way to demonstrate the use of refencing vs embedding. Let's take a few examples.
1-to-many relationships
1-to-many relationships are found in many places. For example: orders have many order line items and beers come from a single brewery and breweries can have many beers they produce.
In document databases, you can choose to represent 1-to-many relationships by either embedding or by referencing other documents. When embedding, you also get the option to embed “1” side in “many” or “many” side in the “1”.
- Embedding “1” in “many” side: This is the case where “beer” contains a “brewery” sub-document.
- Pros: This is advantageous if you have only a few attributes in “brewery” and they are frequently used when accessing beers. With this model, your data access can take advantage of using a “brewery” attribute like “brewery country” to filter the beers to retrieve without a separate retrieval of breweries.
- Cons: This may cause a great deal of data duplication as each “beer” document repeats the brewery details.
- Embedding “many” in the “1” side: This is the case where “orders” embeds “order line items” as an array.
- Pros: When order and order_line_items are frequently accessed together, it makes perfect sense to embed order_line_items in order document.
- Cons: embedding many can be disadvantageous in cases where cardinality of many is too high. For example: In an IoT (internet of things) application, embedding temperature measurements in a thermometer document could be a mistake if you expect many temperature readings over time. Each measurement would make the document perpetually larger. This type of relationships benefit from referencing.
In flexible document databases with full SQL implementations, you are not limited to one of these techniques like embedding or referencing. You can also mix and match: embed some parts and reference in other cases.
Many-to-many relationships
Many to many relationships are not that different from 1-to-many relationships but the number of options multiply. Imagine a case such as “drivers” and “cars” with a many-to-many relationship: A car can have many drivers and drivers can be driving many cars. There are many ways you can represent the relationship. The choice depends on the cardinality of the many-to-many relationship, size of each document, access patterns and performance requirements.
- In the relational world of full normalization, one would create a “relationship” table called “cars_and_drivers” that would reference both cars and drivers. You can do this in a document database as well but you have better options in document databases.
- Typically a better option is to model the many-to-many relationship just like a 1-to-many relationships with one of the “many” side embedding or referencing the other “many” side: For example:
- You can have “car” documents embed an array that references all the “driver” document AND/OR
- You can have “driver” documents embed an array that references “car” documents.
- If you are representing only a few drivers per car or few cars per driver, it may make sense to embed cars in driver documents or drivers in the car document. With the full flexibility of N1QL-like query languages, you can get the shape of the JSON you want from document databases as long as those operators are available in the implementation.
Evolving Data Models
Many applications deal with constantly moving requirements and evolving applications schema is part of their daily life. Unlike relational databases or some of the TABLE-based NoSQL solutions (Cassandra, HBase and more), document databases do not require a schema declaration (i.e CREATE TABLE) or a schema change declaration (i.e ALTER TABLE). The schema of the data is implicit in each document. Developers can simply evolve their applications without any additional administrative action. Schema changes do not require scheduling downtime or trigger long running, offline updates to existing data.
With the given flexibility, developers end up maintaining an evolving schema with versions of their documents in document databases. To accommodate evolving schemas, it becomes important to provide primitives that make it easy for applications to detect various versions of documents. NULL handling can be one way document databases make it easy to handle multiple versions of a shape of a document. Some of the document databases introduce the concept of MISSING. MISSING can be greatly useful for handling evolving schemas.
For example a “beer” document may have evolved over time with version 1 and 2. “Beer” document version 1 explicitly calls out a “canned” attribute to signify if a canned option is available. Version 2 chooses to use a “bottling” attribute that is an array which lists all the bottling options. This evolution in a relational database may require planning and downtime to run operations like ALTER TABLE. However document databases like Couchbase Server can simply house the v1 and v2 side by side without a problem. Developers can simply adapt queries for the older and newer versions of “beer” using clauses like IS MISSING clause in N1QL.
SELECT * FROM `beer-sample`
WHERE type=”beer” AND (
(`bottling` IS NOT MISSING AND `bottling` = [“can”,”glass”]) OR
(`bottling` IS MISSING AND canned=true AND glassed=true));
The flexibility allows evolving the application and the schema without restricting the availability of the database environment.
Conclusion
Relational databases have provided a great deal of support of the past few decades for modeling data. However as applications evolve with complex real life data and as big data systems are required to support complexity and scale of the real life data, relational databases fall short on both flexibility and performance. Document databases provide the best flexibility with JSON documents. However document databases need to be paired with the same flexibilities relational databases offer in querying data and SQL based approach combined with JSON document model can be the best approach for data modelling and data access flexibility.
When picking a document database it is important to note a few important aspects;
- Does the document database natively implement document model (JSON) as its base type or is it retrofitted as an afterthought.
- Does the document database provide powerful flexible query and indexing facilities with full JOINs, NEST/UNNEST operators, array operations and subqueries?
- Does the document database provide good ways of handling evolving schemas with sophisticated handling of both NULLs and MISSING primitives?
About the Author:  |
Cihan Biyikoglu is the Director of Product Management at Couchbase. Before joining Couchbase, Cihan recently worked on a number of products including Twitter Platform, Azure and SQL Server platforms under Microsoft and Microsoft Research. Previously, Cihan Biyikoglu also worked on database technologies such as Illustra and Informix Dynamic Server at Informix. He has a degrees in Database Systems and Computer Engineering. |
References:
- SQL++ : SQL++ is a highly expressive semi-structured query language that encompasses both the SQL and the JSON data model. SQL++ is SQL backwards-compatible. http://forward.ucsd.edu/sqlpp.html
- Couchbase Server: Couchbase Server is a distributed NoSQL database engineered for performance, scalability, and availability. It enables developers to build applications easier and faster by leveraging the power of SQL with the flexibility of JSON. http://www.couchbase.com/nosql-databases/couchbase-server
Share this page

