
 RSS Feed
RSS FeedBlog > Post
Enterprise Search Engines almost double their popularity in the last 12 months
by Paul Andlinger, 2 July 2014
Tags:
Enterprise Search Engines are some kind of a dark horse within the database categories. They are typically not used for storing data, but for searching and analyzing already existing content, which may be either structured data from other databases or rather unstructured content like documents, e-mails etc.
They therefore combine all of the common text searching capabilities - e.g. wildcard searches, stemming and lemmatization - with features like grouping and ranking of search results and faceted search with drill down categories.
As a consequence, Search Engines are optimized for querying data (e.g. by making use of sophisticated index structures and distributed queries), whereas the loading is typically done with lower priority (often in batch mode).
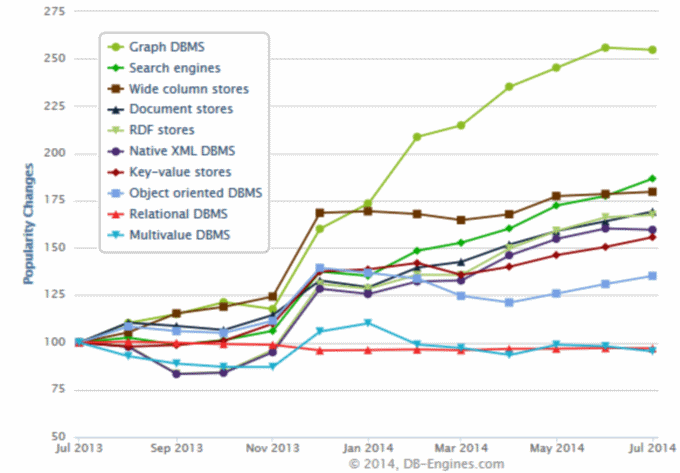
In the last 12 months Search Engines have almost doubled their popularity, making it the second fastest growing DBMS category, only behind Graph DBMS.
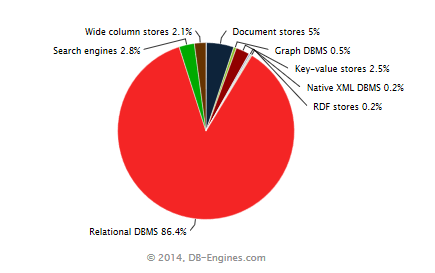
With 2.8% of the overall popularity points, they are now number 3 of all categories, behind the still dominating Relational DBMS and Document Stores.
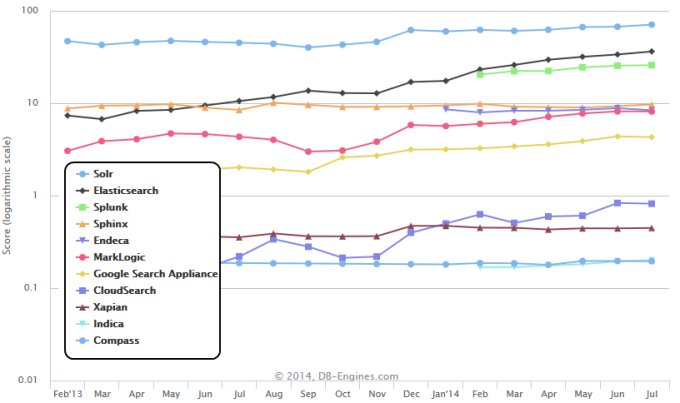
The Search Engines category itself consists of tools mainly used as business intelligence platforms (e.g. Splunk and Endeca) but is lead by two twins (Solr and Elasticsearch), which not only have in common that they are open source, written in Java and based on Lucene. They also share wide application scenarious from yellow page providers to enterprise content management systems.
The following diagram shows the popularity trends of individual Search Engines:
Share this page


