
 RSS Feed
RSS FeedBlog > Post
SingleStore: The Increasing Momentum of Multi-Model Database Systems
by Akmal Chaudhri, SingleStore (sponsor) , 14 February 2022
Tags:
Introduction
Developments in database technology often appear to be cyclical. Go back in time far enough and you’ll see that in the past, hierarchical and network database systems were the norm. Relational database systems eventually replaced older technologies to become today's dominant database technology. But since the early 1990s, we have seen several waves of database technologies come — and sometimes go — including object-oriented database systems, XML database systems and now NoSQL database systems. You read that right: NoSQL is on the way out.
Today, developers face significant challenges in the tools and technologies they must learn. For example, The 2021 Data & AI Landscape lists many modern and emerging technologies. Exciting as this is, there are far too many for developers to learn and master. Company executives must understand how technologies can reduce TCO and improve ROI from a business perspective. Business leaders also face a challenging landscape with deregulation in many industries, leading to competitive and commercial pressures.
These two forces of technology and business may seem at odds. However, modern database technology can provide many technical benefits for developers and help reduce TCO and improve ROI for business leaders: enter the multi-model database system.
Multi-Model Database Systems
SingleStore is a modern, distributed cloud database which natively supports multiple data models. It is built on mature, tried-and-tested distributed data processing techniques and on a relational technology foundation. It can also meet the needs of modern applications that require support for other formats including time-series data, geospatial data, JSON data and more. Figure 1 shows the high-level architecture and we can see the stored data types that support multi-model capabilities.
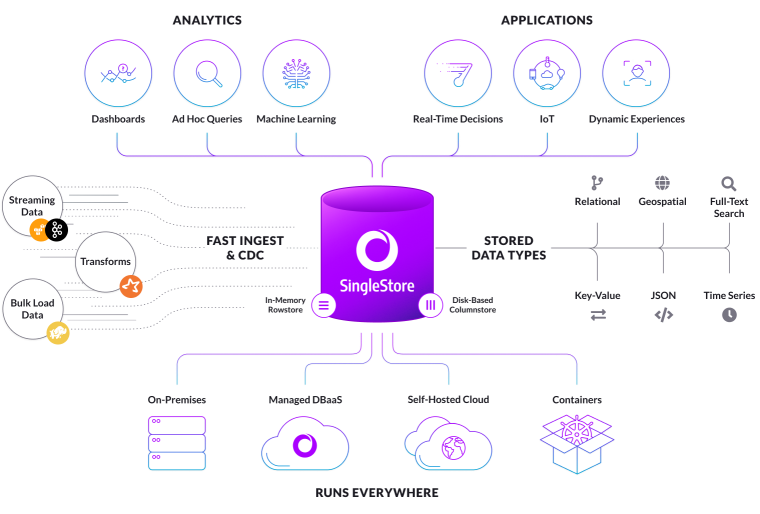
Let's look at four examples of SingleStore's multi-model capabilities in more detail:
1. Time-Series
SingleStore supports functions that can be used with time-series data. Standard SQL already provides a range of useful functions to work with time-series data, but SingleStore has added FIRST, LAST and TIME_BUCKET. Let's look at an example using financial tick data. We can create a table to store tick data, as follows:
USE timeseries_db;
CREATE ROWSTORE TABLE IF NOT EXISTS tick (
ts DATETIME SERIES TIMESTAMP,
symbol VARCHAR(5),
price NUMERIC(18, 4),
KEY(ts)
);
We have a time-valued attribute called ts that uses DATETIME. If we were working with fractional seconds, we could use DATETIME(6). SERIES TIMESTAMP specifies a table column as the default timestamp. A KEY on ts allows us to efficiently filter range values.
We can use time bucketing to aggregate and group data for different time series by a fixed time interval. For example, TIME_BUCKET can be used to find the average time series value grouped by three-day intervals, as follows:
SELECT symbol, TIME_BUCKET("3d", ts), AVG(price)
FROM tick
WHERE symbol = "AAPL"
GROUP BY 1, 2
ORDER BY 1, 2;
We can also combine FIRST, LAST and TIME_BUCKET to create candlestick charts that show the high, low, open and close for a stock over time, bucketed by a three-day window, as follows:
symbol,
MIN(price) AS low,
MAX(price) AS high,
FIRST(price) AS open,
LAST(price) AS close
FROM tick
WHERE symbol = "AAPL"
GROUP BY 2, 1
ORDER BY 2, 1;
In the example above, we use the standard SQL MIN and MAX functions combined with FIRST and LAST to achieve the desired results.
Next, let's look at Geospatial data support.
2. Geospatial
SingleStore supports the Well-Known Text (WKT) format for geospatial data and three main geospatial types: polygons, paths and points. SingleStore supports a range of functions for working with geospatial data. Let's look at an example of how we could store geospatial data for the boroughs of a major city.
We can create a table to store our data, as follows:
USE geo_db;
CREATE ROWSTORE TABLE IF NOT EXISTS london_boroughs (
name VARCHAR(32),
hectares FLOAT,
geometry GEOGRAPHY,
centroid GEOGRAPHYPOINT,
INDEX(geometry)
);
In the above table, GEOGRAPHY can hold polygon and path data. GEOGRAPHYPOINT can hold point data. The geometry column will contain the shape of each city borough, while the centroid will contain the approximate central point of each borough. As we can see, SingleStore can manage geospatial data along with VARCHAR and FLOAT data types.
Another handy feature is the ability to populate a column at load time. Let's look at an example table that holds information about the stations on the subway/underground system for a major city:
id INT PRIMARY KEY,
latitude DOUBLE,
longitude DOUBLE,
name VARCHAR(32),
zone FLOAT,
total_lines INT,
rail INT,
geometry AS GEOGRAPHY_POINT(longitude, latitude) PERSISTED GEOGRAPHYPOINT,
INDEX(geometry)
);
The table above contains information about each station including its name, latitude and longitude. SingleStore will create and populate the geometry column when loading data into the table. This column is a geospatial point consisting of longitude and latitude, allowing us to perform queries against the point data stored in this column using SingleStore's geospatial functions.
We can also store nodes and edges for graphs and networks in SingleStore, and easily reconstruct them for visualizations. For example, Figure 2 shows the London Underground using the latitude and longitude coordinates for stations. It is trivial to retrieve this data from SingleStore and combine it with external libraries to render the visualization.
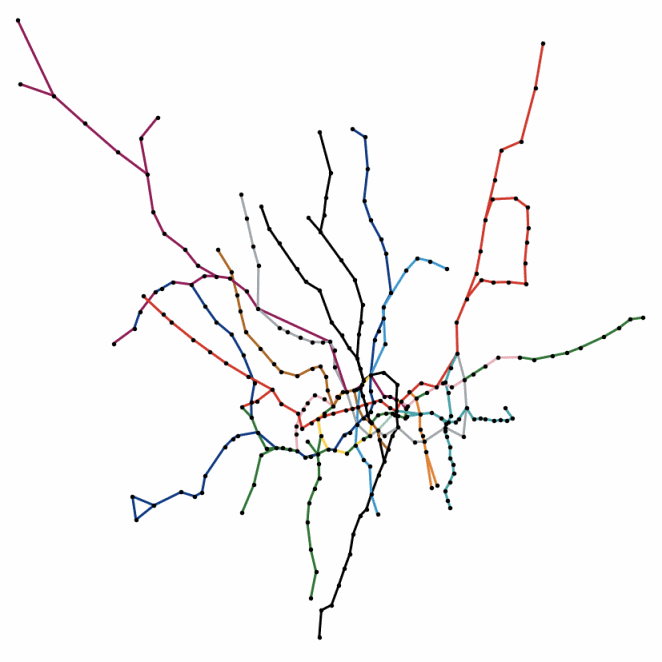
These multi-model capabilities are often combined in a single application. A great example is TrueDigital’s Tracepulse application which combined real-time, anonymized cellphone location data with geospatial and medical supply data to flatten the curve early in the pandemic. Next, let's look at JSON data support.
3. JSON
JSON is a popular data format today and is used in many application domains. For example, JSON could be handy for applications such as e-commerce, where we may be storing a range of products that each have different features. SingleStore supports a JSON type and a wide range of JSON functions that can help manage JSON data.
We can create a table to store e-commerce product data, as follows:
USE e_store;
CREATE TABLE products (
id INT UNSIGNED NOT NULL AUTO_INCREMENT,
name VARCHAR(250) NOT NULL,
brand_id INT UNSIGNED NOT NULL,
category_id INT UNSIGNED NOT NULL,
attributes JSON NOT NULL,
PRIMARY KEY(id),
INDEX CATEGORY_ID(category_id ASC),
INDEX BRAND_ID(brand_id ASC)
);
The products table has a JSON column called attributes. This column uses NOT NULL, enabling SingleStore to raise an error if there is an attempt to store invalid JSON data.
SingleStore can also handle flat JSON structures:
"sensor_type" : "CMOS",
"processor" : "Digic DV III",
"scanning_system" : "progressive",
"mount_type" : "PL",
"monitor_type" : "LCD"
}
arrays:
"body" : "5.11 x 2.59 x 0.46 inches",
"display" : "4.5 inches",
"network" : [
"GSM",
"CDMA",
"HSPA",
"EVDO"
],
"os" : "Android Jellybean v4.3",
"resolution" : "720 x 1280 pixels",
"sim" : "Micro-SIM",
"weight" : "143 grams"
}
and nesting:
"screen" : "50 inch",
"resolution" : "2048 x 1152 pixels",
"ports" : {
"hdmi" : 1,
"usb" : 3
},
"speakers" : {
"left" : "10 watt",
"right" : "10 watt"
}
}
We can use the power of SQL combined with the JSON data. For example:
WHERE category_id = 1
AND attributes::ports::usb > 0
AND attributes::ports::hdmi > 0;
In the example above, the double-colon (::) provides the path to the specific attribute we are interested in. In this case, we are looking for televisions (category_id 1) that have one or more USB and HDMI ports. In the following example, we are checking the os attribute using the SQL LIKE operator:
WHERE category_id = 2
AND attributes::$os LIKE '%Jellybean%';
Document use cases are a special case of key-value use cases where the goal is to simultaneously scale fast writes and fast reads for relatively small amounts of data. My colleague described in detail how to use a multi-model database as a key-value store. Finally, let's look at full-text search support in SingleStore.
4. Full-Text Search
There are many use cases where we may want to perform keyword searches on text, including newspaper articles, journal articles, restaurant reviews, lodging reviews and more. We may need to store and search large bodies of text and return results based on relevancy. Let's look at an example that stores articles from medical journals:
USE fulltext_db;
CREATE TABLE journals(
volume VARCHAR(1000),
name VARCHAR(1000),
journal VARCHAR(1000),
body LONGTEXT,
KEY(volume),
FULLTEXT(body)
);
The body column uses LONGTEXT to store journal article contents. We also create an inverted index on the body column using FULLTEXT.
SingleStore supports the MATCH and HIGHLIGHT functions for use with full-text search. Let's look at examples of these functions. In the following example, we are searching for journal articles that contain the word optometry using MATCH:
FROM journals
WHERE MATCH(body) AGAINST ('optometry');
HIGHLIGHT will return the offset, a unique term count and a small quantity of text. Here is an example query for the word pediatrician:
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician');
SingleStore also supports a range of operators (e.g. +, -), as well as support for fuzzy searches (~) along with single (?) and multiple (*) wildcards. Further details can be found in the documentation.
Summary
This article has taken a quick tour of some of SingleStore's multi-model capabilities. We have seen the versatility and power of the product. Furthermore, we can combine these multi-model capabilities since the whole is greater than the sum of the parts. Using a single product can also eliminate the problem of database sprawl and we also don't need to use polyglot persistence.
SingleStore will save developers considerable time and effort and bring many cost savings to business leaders.
About the Author: |
Akmal Chaudhri is a Senior Technical Evangelist at SingleStore. Based in London, Akmal’s career spans work with database technology, consultancy, product strategy, technical writing, technical training and more. Through his work, Akmal helps build global developer communities and raise awareness of technology. |
Share this page



{kind=link}