
 RSS Feed
RSS FeedBlog > Post
Cloudera's HBase PaaS offering now supports Complex Transactions
by Krishna Maheshwari (sponsor) , 11 August 2021
Tags:
CDP Operational Database is a fully managed cloud-native transactional database with unparalleled scale, performance, and reliability. Optimized to be deployed anywhere, on any cloud platform, CDP Operational Database aligns with the cloud infrastructure strategy best suited for the business. It enables application developers to deliver prototypes in under an hour on their choice of public cloud, with the power to effortlessly scale to petabytes of data. Application developers can deliver mission-critical applications with speed because CDP Operational Database auto-scales, auto-heals and auto-tunes based on workload needs. The underlying database engines it uses are Apache HBase and Apache Phoenix. “We use CDP Operational Database in Microsoft Azure because it allows us to focus on innovating and driving telematics solutions across our organization to better serve our customers. Knowing that we have a reliable application database that can run on any cloud platform or on-premises, allows us to manage all of our data in one place without worrying about usage spikes that can cause downstream application failure, ” said Colin Burn, Connectivity Platform Manager at Daimler Trucks.
HBase provides a non-relational, scale out database while Phoenix provides relational capabilities (i.e., ANSI SQL, secondary indices, star schema, views, etc). Phoenix leverages HBase as a storage backend and HBase uses Block Storage and/or Object Storage as the underlying file store.
What is ACID?
The ACID model of database design is one of the most important concepts in databases. ACID stands for atomicity, consistency, isolation and durability. For a very long time, strict adherence to these four properties was required for a commercially successful database. However, this model created problems when it came to scaling beyond a one server database. To accommodate this limitation, customers scaled up the hardware on which the databases were deployed.
What is an atomic transaction?
A transaction comprises a set of operations that are atomically managed. Meaning all the operations are either fully complete (committed) or have no effect (aborted).
Apache HBase and Apache Phoenix support single-row atomic transactions. Cloudera Operational database builds upon Apache Phoenix to provide support for complex multi-row / multi-table transactions, meaning that developers can implement traditional star schema, wide columns, or both together when using our relational capabilities. This flexibility combined with the Operational Database’s evolutionary schema approach allows developers to take advantage of a modern scale-out database while utilizing their existing knowledge of how to write applications that use traditional relational databases.
Cloudera’s implementation, like other relational databases, allows application developers to open a transaction, conduct an arbitrary number of CRUD operations and commit. When the commit process is executed, it ensures that all of the statements are done as if they were a “single” operation (i.e., atomically) and if they are not able to complete due to a conflict, they are all aborted just like a transaction would happen for a single row.
What is meant by lock-free for transactions?
Transactional databases must support highly concurrent access from thousands of simultaneous clients each conducting a high frequency of transactions. Each transaction can involve accessing & modifying a number of rows across a number of tables. In large databases like Cloudera’s OpDB, these transactions will often span nodes in the cluster as well.
This means that conflicts are guaranteed to happen.
There are two approaches to resolving conflicts: locking and not-locking (i.e., lock-free).
Locking approaches require the client application to acquire a lock on each row (or cell) that will be modified before making a commit. Once locks are acquired, these rows (or cells) must wait for the lock to be free before acquiring a lock and writing to them. Once the updates are completed, a ‘commit’ results in writing the data to all the cells and removing all of the locks. Many application developers are experienced with race conditions from circular dependencies that can cause applications to hang (i.e., deadlock or livelock). Locks were also the cause of dramatically poor performance on the part of an application as applications waited on each other so that they could get a lock and proceed.
Cloudera uses a lock-free implementation. By definition, this implies that both deadlocks and livelocks are not possible and transactions can always progress. When a ‘commit’ happens, each transaction’s set of tables/rows that are being written to are checked to see if any other transactions made writes to them during the course of the transaction. If so, the transaction aborts, if not, it completes successfully. This behavior trades off slowness due to locks for fast-failing and giving clients more control over how to react to the failure (i.e., retry) and ends up with more predictable performance.
This progress of lock resolution prevents any slow-down to the entire ecosystem of applications running simultaneously on the database. It also allows linear scalability while providing the atomicity that traditional transactional databases provide.
Another complication that arises is what happens to the data when writes impact reads. This is solved through snapshot isolation.
What is meant by snapshot isolation?
Isolation in ACID refers to the ability to prevent multiple clients from interfering with each other. There are many different types of isolation that have been implemented by different databases and each has a different implication on the clients that developers build. We provide “Snapshot Isolation.” Snapshot Isolation provides a consistent view of the database during the course of a transaction. In other words, we effectively present a “frozen” (or snapshotted) view of the data at the time a transaction starts. The only way a value changes in the course of a transaction is when it is changed during the course of the transaction itself.
Transaction guarantees
Data is snapshotted at the beginning of every transaction and that snapshot is used for all subsequent queries within that transactions context. Thus, any changes made in the transaction scope are not visible to any other transaction that is happening in parallel. When a transaction completes, those changes are reflected in the database in their entirety and other transactions will fail.
This approach allows us to scale the number of simultaneous transactions linearly as the database scales from a compute capacity basis.
Performance results
Current testing includes the industry standard TPC-C benchmark using the OLTP Bench application. The TPC-C benchmark simulates a number of purchases conducted simultaneously across a number of warehouses. The schema used in TPC-C are represented in following entity-relationship diagram:
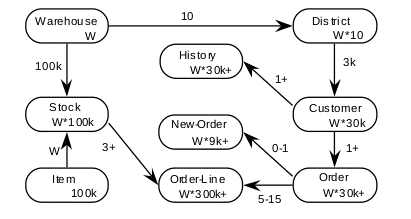
The numbers in the entity blocks represent the cardinality of the tables (number of rows). These numbers are factored by W, the number of Warehouses, to illustrate the database scaling. The numbers next to the relationship arrows represent the cardinality of relationships(average number of children per parent). + symbol represents the number small variation of database population.
An order placement requires the following 10 queries to be run as a single atomic transaction:

A payment transaction requires the 6 following queries to be run as a single atomic transaction:

With 45 region servers running on Dell PowerEdge R440 nodes, we were able to achieve the following results:
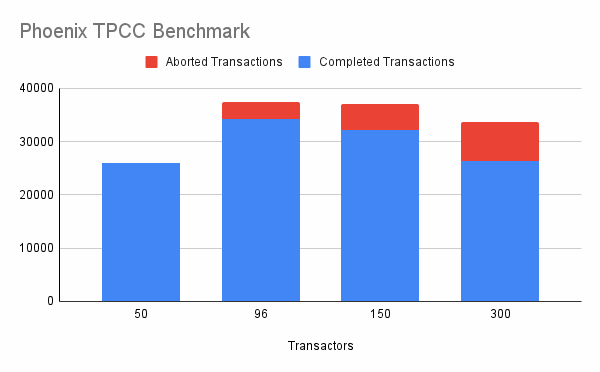
In this graph, the Y-axis represents the number of orders that can be fully processed (including new order creation, payment, delivery etc.) per minute and is expressed in the TPM-C benchmark. The X-axis represents the number of entities executing transactions in parallel. This number is expected to scale linearly as the scale of the cluster grows and shrinks. When combined with CDP Operational Database experience -- you automatically utilize the infrastructure required to get the required throughput at the time it is required.
Conclusion
If you are struggling managing applications that have overgrown their relational databases or are looking to build a transactional application that leverages more data than can fit in a single server -- Try CDP Operational Database for free with Test Drive.
About the Author: |
Krishna Maheshwari is a Senior Director of Product Management at Cloudera responsible for the Operational Databases and Replication Technologies. He has deep expertise in building cloud native platforms and technologies and has built multiple products that have simplified customers' cloud journeys. |
Share this page

