

 RSS Feed
RSS FeedBlog > Post
GQL - initiating an industry standard property graph query language
by Alastair Green (guest author), 30 May 2018
Tags:
The idea was expressed in “The GQL Manifesto”, which you can find at gql.today. It went out on May 13, a couple of days before a joint meeting in Toronto of the ISO and U.S. standards groups that are responsible for the SQL standard.
The front page includes a poll: over 2,600 have voted on the proposition “Should the property graph community unite to create a standard Graph Query Language, GQL, alongside SQL?” and from day one (when the first thousand votes came in) the result has sat at around 95.4% Yes to 4.6% No.
There are planned extensions to SQL for property graph read queries (which Neo4j is helping to develop alongside Oracle, Microsoft, IBM and SAP), but those are limited enhancements for existing relational stores. “Native” graph databases or services don’t naturally relate to SQL. The property graph data model is a superset of the tabular SQL model, so it feels right to have a graph query language, GQL, that complements SQL.
Benefits of Fusing Three Languages into One Standard
Property graph databases store data the same way that data is viewed in a conceptual “entity-relationship” model, familiar to data designers the world over. When you map an ER model to relational databases, you have to create foreign keys and link tables: in the graph data model, links or relationships are stored directly. Nodes and edges represent the topology of your data, and properties on those two kinds of structural entities hold data values (just like ER model entity attributes).
There are three existing pure graph languages which use a shared “graph pattern” or “motif” metaphor for inserting, updating or extracting data from a property graph. PGQL comes from Oracle PGX (first appearing in 2016); openCypher started out in Neo4j’s graph database in 2011 and is now used in four other commercial products. (Both languages have also been used in research projects.) G-CORE is a research language, described in a SIGMOD ‘18 paper written by several academics, as well as language designers from four industry vendors, working in the LDBC Query Language task force.
(If you want more detail, there’s a great technical survey comparing the three languages at the gql.today site, which my colleague Stefan Plantikow presented to the SQL standard committee, WG3. Stefan’s paper has links to all the relevant specifications and papers.)
All three of these languages have “ASCII Art” syntax to “draw” patterns of interest in a graph. Let’s use PGQL syntax to illustrate this, with a read query:
SELECT
c.name AS customer_name,
o.number AS order_number,
o.date AS booking_date
FROM GRAPH
sales_orders
MATCH
// graph pattern
(c:Customer)->[o:ORDER]->(:OrderBody)<-[:SALE]-(p:Product)
WHERE
p.number = ’PT6708-23’
The pattern means that all data in the graph that matches the sequence of nodes and edges (each of which has a particular “label” or element type) will be identified. This operation lifts a “sub-graph” or a “projected graph” of sales orders for a particular product into the application. Properties on all instances of :Customer nodes or :ORDER edges that match can now be read by the application. In PGQL this is achieved by a SELECT statement.
The three languages are very close relatives in terms of syntax and basic semantics. The Cypher equivalent of the sales order query we just showed is exactly the same, but puts a clause
RETURN
c.name AS customer_name,
o.number AS order_number,
o.date AS booking_date
at the bottom of the query, in place of the SELECT clause that PGQL positions at the top of the query. Cypher allows multiple queries to be chained, top to bottom, so the table coming out of one can feed the next. Despite that difference, this example shows how similar these two languages are.The same goes for G-CORE, which uses Cypher syntax with some PGQL variants, to form a base language used to explore newer features like graph query composition (“graph construction”).
The idea is to fuse these three dialects into one standard language, GQL. That makes sense, not just because the languages look and feel very similar, but because if you combine all their features you get a full-featured graph query language that lets you create, read, update and delete data.
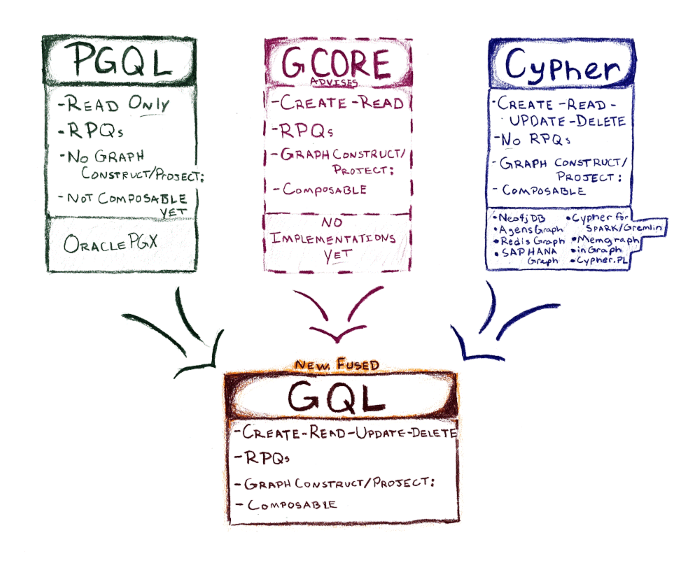
You also get two key advances. PGQL lets you use regular expressions in your path patterns, which makes them even more flexible and expressive. (They are already very convenient, terse but intuitive ways of expressing complex linkages that blow out in SQL to impenetrable join queries, easily running into many hundreds of lines of code.) PGQL shows this feature:
PATH
connects_to
AS
(:Generator) -[:has_connector]-> (c:Connector)
<-[:has_connector]- (:Generator)
WHERE c.status = 'OPERATIONAL'
SELECT
generatorA.location, generatorB.location
MATCH
(generatorA) -/:connects_to+/-> (generatorB)
connects_to here is a kind of named “pattern view”, which can be very useful for modularizing and simplifying code. The path expression means “the circuits that connect generators A and B through operational connectors”.
The second aspect is composable querying, along with multiple named graphs. In Cypher for Apache Spark and in PGQL there is a concept that pattern matching occurs with respect to a named graph, one out of many that may have been created prior to the read query executing. (The PropertyGraphCatalog in the Spark project registers graphs; a similar concept is proposed in SQL for graphs that map over tabular data, via new DDL.)
In Cypher for Apache Spark and in G-CORE the next step is clear: queries that can project graphs as well as tabular data; and queries which can accept as input more than one graph at a time. New graphs can be created by combining graphs, or fusing sub-graphs from input graphs (and brand new data like new relationships can be added in the process). This opens the road to named graph-projecting queries (like SQL views), which have many uses, not least in masking sensitive properties to limit access for unprivileged users and in helping to abstract and encapsulate chunks of functionality.
If we look again at the example query I showed for MATCHing and projecting data, we can see how it could be modified to project a sub-graph:
ADD GRAPH texas_sales_orders
{
FROM GRAPH
sales_orders
MATCH
(c:Customer)->[o:ORDER]->(:OrderBody)<-[:SALE]-(p:Product)
WHERE
c.state = ’TX’
RETURN GRAPH
}
In that simple example we are just slicing out a subset of the input graph, which would pull in all the orders placed by Texan customers, and the associated products.
Two more changes would let that become a parameterized named query or view:
ADD QUERY state_sales_orders
{
FROM GRAPH
sales_orders
MATCH
(c:Customer)->[o:ORDER]->(:OrderBody)<-[:SALE]-(p:Product)
WHERE
c.state = ’$state’
RETURN GRAPH
}
Which would let us restate our first query in a more succinct way:
FROM
state_sales_orders // let $state = ’TX’: named query or view graph
MATCH
(c:Customer)->[o:ORDER]->(:OrderBody)<-[:SALE]-(p:Product)
RETURN
c.name AS customer_name,
o.number AS order_number,
o.date AS booking_date
We're already looking at other features GQL could inherit or extend from its source languages and there's a lot of opportunity to further improve modeling and implementation.
Why GQL Now?
First, changing another language like SQL or SPARQL to make it become fully “conversant” with property graphs is not easy or smart. We think that a language per data model is not a bad guideline. And property graph products and services like Azure CosmosDB, Neo4j or Amazon Neptune don’t sit on top of SQL engines: we need a language designed for the graph querying job, irrespective of the implementation. Then let the languages interweave where necessary: fold an RDF graph into a GQL view, perhaps.
Second, SQL extensions for property graphs let you view tables as a graph and run read-only pattern matches to give back a tabular result set, which fits nicely into SQL clients and as a SQL sub-query. That’s reasonable, but anything more advanced, like graph queries that are functions over graphs, which return graphs, don’t fit at all naturally into SQL and will not be part of the SQL:2020 standard. A consensus on a practical and limited scope for SQL was arrived at earlier in May, and that made it clear that there would be no major confusion between SQL and GQL.
Third, the “property graph query language” community has gone through a big burst of work in the last eighteen months, all pointing in very similar directions, across research and industry. The LDBC work which led to the G-CORE research language was not restricted to table extraction. The four vendors involved in that work (Oracle, Neo4j, Capsenta and SAP), joined hands with researchers with long backgrounds in path querying and with a history of working on SPARQL, to formalize graph query composition (and a concept of adding paths with their own properties as first class entities in a graph). G-CORE examines regular path queries and discusses issues of computational complexity and their bearing on language design. (There are a number of graph operations like asking for all the paths in a graph, or “sub graph isomorphism” [give me a sub-graph that has no repeated edges or nodes], which are not generally tractable, even if they may work on small datasets.)
GQL is a proposal to channel a period of convergent, criss-crossing and occasionally turbulent intellectual labour into an industrial standard that reflects more than five years of practical property graph querying, lives up to G-CORE’s aspirations and avoids idle variation.
It’s going to take a lot of very hard work and a lot of patience and willingness to compromise, but it’s also an exciting and promising prospect.
If you’re interested in helping in any way with making GQL a reality, please get in touch via the gql.today contact page! My view is that the process of designing and drafting the standard should be as open and as international as possible.
About the Author: |
Alastair Green leads the Query Languages Standards and Research group at Neo4j Inc. He’s the product manager for Neo4j’s forthcoming Morpheus product (using Cypher for Apache Spark) and liaises with Neueda Ltd’s Cypher for Gremlin project team on direction and design. Alastair has worked for product vendors and enterprise end-user companies: for four years recently he led the Enterprise Data Distribution Infrastructure project at Barclays Investment Bank, which included an extended DocumentSQL language as part of a WAN-scale streaming query processor for end-of-day high-volume file data. He has a long history of working in the area of transaction management, and is a co-author of the OASIS Business Transaction Protocol standard. |
Share this page

