

 RSS Feed
RSS FeedBlog > Post
The openCypher Project: Help Shape the SQL for Graphs
by Emil Eifrem (guest author), 22 December 2015
Tags:
Let’s face the facts: Graphs are going mainstream.
If you take a look at the DB-Engines ranking for December 2015, you can see that graph databases are the clear leader in terms of popularity growth over time.
As graph technologies go mainstream, more and more vendors are entering the space, and I’m not just talking about startups. Big database industry players are now getting into the graph database game, from Oracle and IBM to Datastax and Amazon.
All of this wonderful free-market competition is certainly a big win for users who are now going to have more choices – with more features and better performance – than ever before.
At the same time, having a plethora of graph options also means a plethora of graph query languages to learn, especially if you ever want to switch vendors or explore other options.
Almost every time I speak with an enterprise CIO about adopting a graph database solution, they’re excited about the power of graph databases, but they’re averse to using a query language that’s attached to a single vendor.
Moving forward, it’s clear that everyone (both customers and vendors) benefits if we can all agree on a common graph query language.
The Analogous Stories of SQL and Cypher
Right now, I believe graph databases are at the same point that relational databases were in the mid-1980s.
There were many vendors out there, and they were all working hard to implement the relational paradigm in the best way possible. They invented all kinds of amazing technology and all sorts of ways of interacting with their relational database.
But one of the key trigger points in order to make the relational space go mainstream was, of course, that all the vendors eventually came together and started to collaborate around a structured query language for the relational database: SQL.
I think we’re at exactly that moment right now in the graph space, because we’re already seeing that cross-vendor collaboration. That’s why I am excited about the openCypher project,.
As more users start using graphs and as more vendors enter the graph technology space, we’re at a time when a common graph query language – agnostic of vendor or platform – will be a huge benefit to both vendors and users.
The biggest value of a shared graph query language is reusability.
If a developer can use the same query language while working with Oracle, Apache Spark, IBM or Neo4j – then we all win. Because a wider graph industry encourages healthy competition, which is a benefit to all users.
Why Cypher
Cypher is the graph query language that was introduced in the Neo4j 1.x series (and made a first-class citizen in 2.0).
After that, the popularity of graph database technology took off completely, as witnessed in the DB-Engines category ranking.
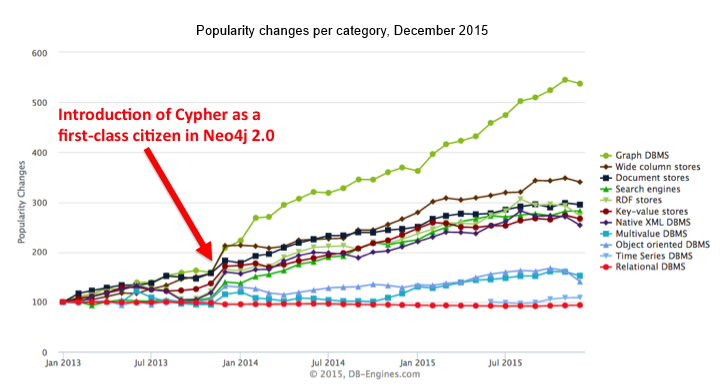
Cypher uses symbols to express patterns that correspond to a visual understanding of data, making it particularly well-suited to the challenges of querying connected data (i.e., graphs).
As a declarative query language, Cypher lets users focus on their respective domain and express what data to retrieve, instead of getting lost in the mechanics of data access.
The best part is that Cypher draws upon the strengths of the many great query languages that came before it. Many of the keywords, such as WHERE and ORDER BY are drawn from SQL itself, while other aspects, such as pattern matching, are borrowed from SPARQL. And other collection semantics have been borrowed from languages such as Haskell and Python.
Graph databases are whiteboard friendly – Cypher makes them keyboard friendly.
So, Who Else Is in on the openCypher Project?
While we love Cypher, we don’t expect you to take our word for it. What makes the openCypher project powerful is that we aren’t the only one who uses it.
My friend Dan McClary from Oracle is just one of the first vendors who will use Cypher in a non-Neo4j product. This last summer, Dan and his team launched Oracle Big Data Spatial and Graph, which looks at large-scale complex analysis of graphs in the big data space.
For the Oracle team, getting behind the openCypher project was an obvious move for joining the graph community.
One of the things Dan told me was that his team was really interested in how to provide more functionality on top of graphs to bring graph analysis to more and more use cases. And while SQL is great for relational databases, Dan believes that Cypher is “going to be transformative in analytics over the next five years.”
Catch the rest of Dan’s comments about Cypher and Oracle in this video.
Another major player to adopt Cypher is Apache Spark (commercially underwritten by Databricks). I personally believe that Spark will dominate the entire analytics space for at least the next five years.
Through the openCypher project, Cypher will become the default query language for all graphs processed through GraphX, Apache Spark’s API for graphs and graph-parallel computation.
My friend Ion Stoica – the CEO and Founder of Databricks – told me he’s looking forward to bringing Cypher’s graph pattern-matching capabilities into the Spark stack, “making graph querying more accessible to the masses.”
ThoughtWorks is also taking part in the openCypher project. Their CTO, Rebecca Parsons, believes that the one thing holding back wider adoption of graph databases has been the lack of a widely supported, standard graph query language.
She sees openCypher as “an important step towards the broader use of graphs across the industry.”
Other members of the openCypher project include Tableau, Structr, Tom Sawyer Software and many others (see a full listing here).
What the openCypher Project Includes
The openCypher project delivers four key artifacts released under a permissive license:
1. Cypher reference documentation:
A comprehensive user documentation describing use of the Cypher query language with examples and tutorials.
2. Technology compatibility kit (TCK):
The TCK consists of a number of tests that a software supplier would run in order to self-certify support for a given version of Cypher.
3. Reference implementation:
Distributed under the Apache 2.0 license, the reference implementation is a fully functional implementation of key parts of the stack needed to support Cypher inside a data platform or tool.
The first planned deliverable is a parser that will take a Cypher statement and parse it into an AST (abstract syntax tree) representation. The reference implementation complements the documentation and tests by providing working implementations of Cypher – which are permissively licensed – and can be used as examples or as a foundation for one’s own implementation.
4. Cypher language specification:
Licensed under a Creative Commons license, the Cypher language specification is a technical expression of the language syntax to enable parsers to auto-generate the query syntax. A full semantic specification is also planned.
How You Can Help Shape the Future of openCypher
While openCypher has certainly attracted big players like Oracle, Spark and ThoughtWorks, we’re just as interested in suggestions from the wider Cypher community.
We want the evolution of the Cypher query language to be as open as possible. If you’re passionate about graph querying, then we want you on board.
openCypher is a work in progress, and in the next few months, we will move more and more of the language artifacts over to GitHub for wider availability. But in the meantime, join our Google Group to stay on the cutting edge of new openCypher developments.
The Cypher query language has already opened up worlds of opportunity to the graph ecosystem; openCypher aims to open up many more.
About the Author:  |
Emil is the founder of Neo4j, the most widely deployed graph database on the planet, and CEO of its commercial sponsor, Neo Technology. He plans to save the world with graphs and own Larry's yacht by the end of the decade. He tweets at @emileifrem. |
Share this page

