

 RSS Feed
RSS FeedBlog > Post
AntDB: Answer to Database Evolution - Hyperconverged All-in-One Streaming Engine
by Bei Mo, AntDB (sponsor) , 22 June 2023
Tags:
Introduction
In our point of view, HTAP, lake/warehouse integration and stream/batch integration are only transitional products on the evolution of database. The future database will put “data” at its core and integrate with various business data to meet IT systems and industrial data in China.
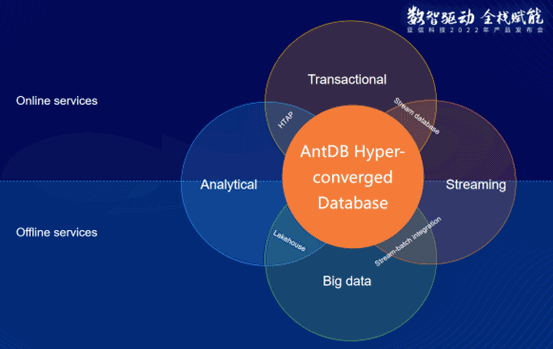
Figure 1. Hyper-convergence Architecture of AntDB
Integration of five application requirements:
Traditional transaction and analysis, streaming processing, time-series and memory computing
The current application demands of subscribers for data mainly lie in five aspects: traditional transaction, analysis, big data mining, high-performance memory computing and real-time streaming data processing. These five aspects are carried separately by different technology stacks. HTAP is attempting to integrate transactions and analyses while AntDB aims to bring the five types of data services under a unified technical framework, making one product a "one-stop service" for subscribers.
The hyper-convergence framework of database proposed by AntDB V7.2 can make full use of the architectural advantages of distributed database engines and further expand on the concept of HTAP to encapsulate multiple engines such as time-series storage, streaming processing execution and vectorized analysis in a unified architecture. Supporting multiple business models in the same database cluster greatly reduces the complexity of supporting diverse data requirements for business systems and brings convenience to application developers as well as DBAs and architects.
Born to change: AntDB’s new-generation streaming processing engine
If the hyper-convergence framework is the basic architecture of database and does not solve a specific type of scenario problem, then AntDB-S streaming data engine of AntDB V7.2 completely overturns the design and development model of real-time computing applications.
The problems of difficult development and high cost of streaming business affect the rapid promotion and implementation of streaming computing in actual production. Other mainstream stream processing frameworks focus on the “processing” itself. Since they do not have database capabilities, they require complex data extraction when they need to interact with other data for correlation and temporary storage,and manual processing operations is required inside the streaming processing engine via Java/Scala program code.
After more than ten years of practical experience in core business scenarios of carriers, AntDB found that some business scenarios cannot be realized by traditional technology and need real-time processing capabilities to support such as streaming computing.
Therefore, AntDB has done a lot of innovative explorations and research from scratch to integrate streaming computing into the database kernel. Users can freely define the structure of data and real-time processing logic through standard SQL under the framework of one database engine; meanwhile, data can flow freely between stream objects and table objects inside the database; users can conduct performance optimization, data processing, cluster monitoring and business logic customization of data by establishing indexes, stream-table association, triggers, materialized views, etc. at any time.
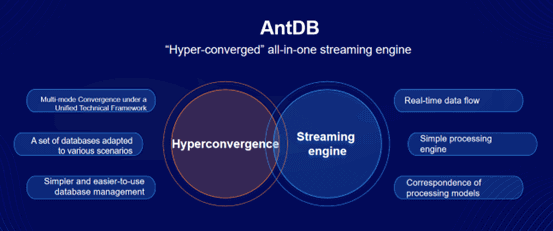
Figure 2. Hyperconvergence + Streaming
Under AntDB's all-in-one streaming engine mechanism, developers can get rid of the complexity of real-time business development and do not need to use Java/Scala code to define data processing logic; and for operation and maintenance personnel, they can achieve the goal of "one product to meet multiple data processing types", which greatly reduces the complexity of the overall technical framework, and the security stability and development efficiency of the system are improved.
Evolution of AntDB
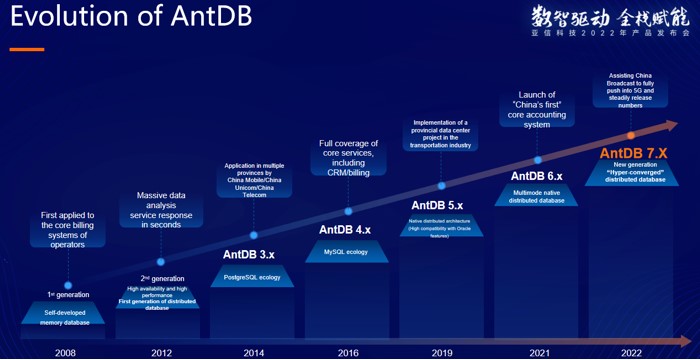
Figure 3. Evolution of AntDB
According to the developer and engineer of the first generation of AntDB, based on the communication demand of a super province, the R&D team of AsiaInfo was “commissioned” to take over the task, and without any experience and products to refer to, they learned from textbooks little by little, wrote code line by line, then ran the system for testing, and worked overtime to refine the product, and finally, the throughput rate and response time of the whole transaction processing were improved by an order of magnitude compared with the other mainstream databases on the basis of telecom-level high availability, and the first-generation AntDB, the in-memory database was born.
With the iteration of communication technology, AntDB has also kept pace with the times and completed the "three-step jump": from in-memory database to full-featured, general-purpose relational database, to a full-stack database compatible with MySQL and PostgreSQL open source ecology and highly compatible with foreign mainstream databases, and further to distributed, multi-model cloud-native database.
In the face of increasingly complex mixed load scenarios and mixed data type business needs in the future, and considering the increasingly demanding data needs of subscribers in real-time processing scenarios such as real-time analysis and real-time reporting, and asynchronous transaction scenarios such as Internet+, AntDB has proposed a new concept of "hyper-convergence" and "stream-batch integration" based on the overall architecture to evolve into a future-oriented database. In the future, AntDB will continue to evolve based on new cutting-edge technologies and application scenarios, and continue to iterate and upgrade.
For application cases, please check our website.
About the Author: |
Bei Mo, technical director of AntDB After 15 years of database R&D and service, he has mastered profound database technology and knowledge and rich experience in field support and project management in the new technology development wave such as mobile Internet, Internet of Things, cloud computing, etc. Since he became the technical director of AntDB, he has deeply researched the future-oriented cutting-edge database technology and promoted the application of "hyper-converged architecture" and "streaming real-time data warehouse engine" and other database technologies in telecom, transportation, finance, energy and other industries. |
Share this page


