

Enzyklopädie > Artikel
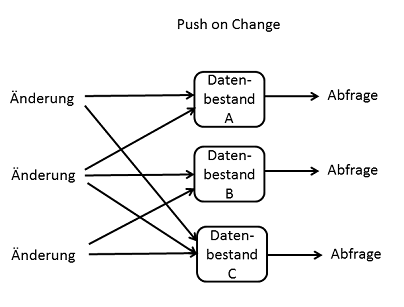
Push on Change
"Push on Change" ist ein Prinzip der Datenmodellierung, das häufig bei NoSQL Datenbanken zum Einsatz kommt. Die Idee ist, bei einer Änderung die Daten eher redundant mehrfach zu verteilen, um danach Abfragen möglichst einfach zu halten.
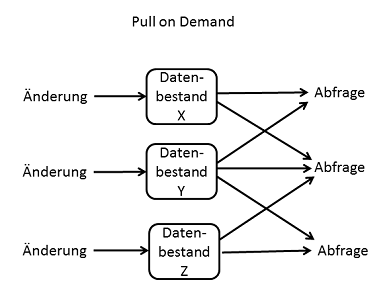
Pull on Demand
Das gegenteilige Prinzip ist "Pull on Demand", bei dem eine Änderung der Daten möglichst an wenigen Stellen erfolgt, mit der Konsequenz dass bei nicht-trivialen Abfragen die Daten von mehreren Stellen gesammelt werden müssen.
Anwendung
Welches der beiden Prinzipien besser ist, hängt lediglich von den Anforderungen der Applikation ab, etwa die Häufigkeit und Komplexität der Änderungen bzw. der Abfragen.
Tendenziell ist es allerdings so, dass in relationalen Datenmodellen durch den Versuch der Normalisierung eher Pull on Demand zum Einsatz kommt, während bei NoSQL Lösungen, wo komplexe Abfragen von der Technologie weniger unterstützt werden, eher Push on Change favorisiert wird.
Skalierbarkeit
Es ist auch zu beobachten, dass bei sehr großen Datenmengen Push on Change leichter skalierbar ist. Der Grund dafür ist, dass der Aufwand für das Schreiben von Daten kaum mit der Datenmenge ansteigt. Der Nachteil ist allerdings das Risiko der Dateninkonsistenz aufgrund von Fehlern.
Im Gegensatz dazu steigt bei Pull on Demand der Aufwand bei komplexe Abfragen sehr stark mit der Datenmenge. Aus diesem Grund werden die Daten auch bei relationalen Datenmodellen aus Performancegründen häufig teilweise denormalisiert, wodurch eine Mischform der beiden Prinzipien entsteht.
Beispiel
Der Unterschied zwischen Push on Change und Pull on Demand sei an einem einfachen Beispiel verdeutlicht. Angenommen es sollen in einem Online Forum User und Forumsbeiträge abgespeichert werden. Auf der Profilseite jedes Users soll das Datum seines letzten Beitrages und die Anzahl seiner Beiträge angezeigt werden.
Bei Pull on Demand würde man dazu immer wenn die Profilseite generiert wird, alle seine Beiträge zählen, das letzte Datum ermitteln und anzeigen. Bei Push on Change würde man beim Abspeichern eines neuen Beitrages das Datum nicht nur im Beitrag selbst, sondern auch beim User abspeichern, und einen Zähler beim User erhöhen. Bei der Anzeige bräuchte man dann nur noch direkt beim User abgespeicherte Daten anzuzeigen.
Bei Push on Change hätte man einen etwas höheren Speicherbedarf, und einen höheren Aufwand beim Erstellen von Beiträgen, welcher allerdings - und das ist wesentlich - nicht von der Anzahl der Beiträge abhängt. Bei Pull on Demand hat man keinen zusätzlichen Aufwand beim Abspeichern von Beiträgen, man hat auch keinen Aufwand bei etwaigem Löschen von Beiträgen um die redundanten Daten auf Stand zu halten, dafür hat man beim Generieren des Profils einen Zusatzaufwand, welcher sehr wohl von der Anzahl der Beiträge abhängt.

